一.监控告警
1.监控告警架构
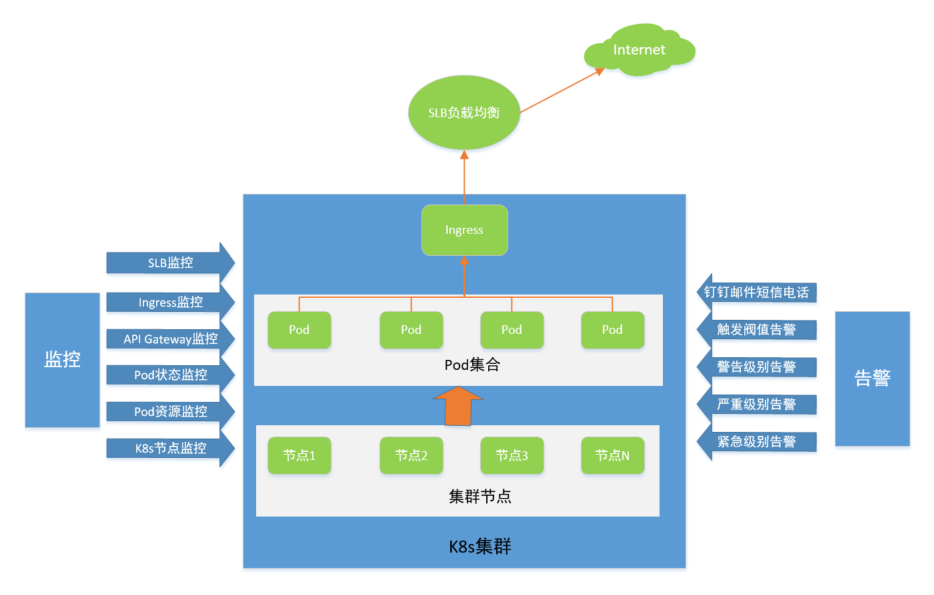
从上图中,我们可以清晰的看到Kubernetes平台监控体系,总体分为三层,即K8s节点层、Pod集合层、Ingress层和API Gateway层(若有)。按照告警级别来分,可分为警告、严重、紧急告警,告警使用钉钉、邮件、短信和电话等方式。如下简要的做说明。
Kubernetes定义了三种不同的监控数据接口,分别是Resource Metric,Custom Metric以及External Metric,如下所示。
- Resource Metric:通常是Metrics-Server进行采集的,提供的主要是Pod、Node、Namespcae等Kubernetes中内置逻辑对象的监控;
- Custom Metric:是用户自定义的监控指标,通常是通过Prometheus进行采集,再通过Horizontal Pod Autoscaler(自动弹性伸缩)进行消费;
- External Metric:主要针对外部指标,通常是面向云场景的,例如希望在Kubernetes集群中获取SLB的最大连接数作为弹性指标或者其他云服务的监控指标,那么通常是通过云厂商的External Metric实现来提供的,目前阿里云的alibaba-cloud-metrics-adapter提供了SLB、SLS(Ingress)、云监控等指标。
此处,针对Kubernetes平台的Pod层进行监控告警,我们使用Resource Metric(由Metrics-Server实现)和Custom Metric(由Prometheus实现)这两种监控数据接口。这里,简单介绍下Prometheus。
2.什么是Prometheus
谈K8s或Docker监控,Prometheus不得不谈。Prometheus 作为容器生态下集群监控的首选方案,是一套开源的系统监控报警框架。它启发于 Google 的 borgmon 监控系统,2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。和传统的监控工具如Zabbix使用Push模式不一样,Prometheus使用Pull模式(即server端主动从exporter监控端拉取最新的数据,避免有问题的服务器推送有问题的指标 (metrics))。
Prometheus 优势
- 灵活的数据模型:在 Prometheus 里,监控数据是由值、时间戳和标签表组成的,其中监控数据的源信息是完全记录在标签表里的;同时 Prometheus 支持在监控数据采集阶段对监控数据的标签表进行修改,这使其具备强大的扩展能力;
- 强大的查询能力:Prometheus 提供有数据查询语言 PromQL。从表现上来看,PromQL 提供了大量的数据计算函数,大部分情况下用户都可以直接通过 PromQL 从 Prometheus 里查询到需要的聚合数据;
- 健全的生态: Prometheus 能够直接对常见操作系统、中间件、数据库、硬件及编程语言进行监控;同时社区提供有 Java/Golang/Ruby 语言客户端 SDK,用户能够快速实现自定义监控项及监控逻辑;
- 良好的性能:在硬件资源满足的情况下,Prometheus 单实例在每秒采集 10w 条监控数据的情况下,在数据处理和查询方面依然有着不错的性能表现;
- 优秀的架构:采用推模型的监控系统,客户端需要负责在服务端上进行注册及监控数据推送;而在 Prometheus 采用的拉模型架构里,具体的数据拉取行为是完全由服务端来决定的。服务端是可以基于某种服务发现机制来自动发现监控对象,多个服务端之间能够通过集群机制来实现数据分片。总之就是太牛逼,学不过来。
基于Prometheus监控Kubernetes的整体服务架构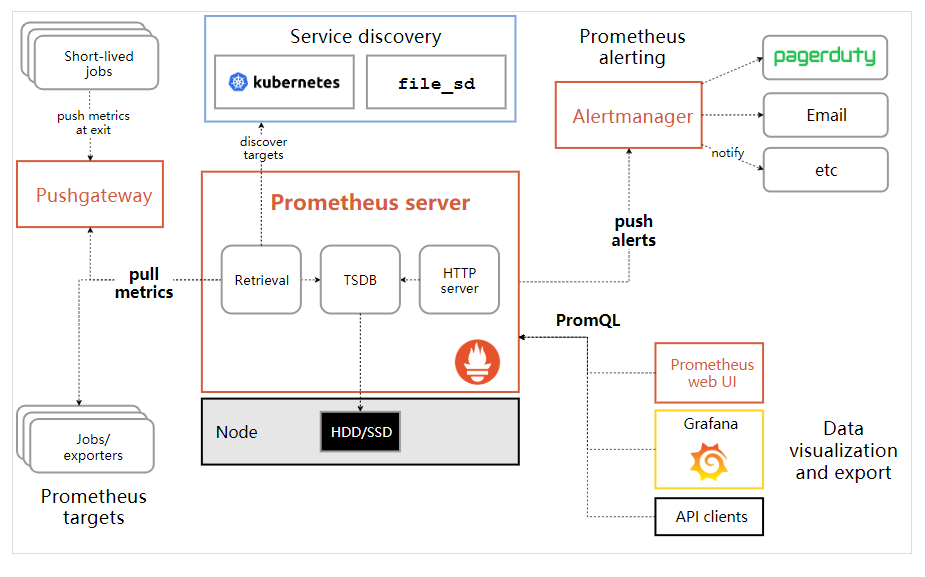
图:https://www.cnblogs.com/kevingrace/p/11151649.html
针对Kubernetes监控告警,需要的组件如下所示:
- metric-server:从api-server服务中获取cpu、内存使用率这种监控指标,可集成prometheus存储数据,他当前的核心作用是为HPA等组件提供决策指标支持。也用于收集apiserver,scheduler,controller-manager,kubelet组件数据。
- kube-state-metrics:获取k8s各种资源的最新状态,如Pod、service、endpoint、deployment等内置逻辑对象的数据,之所以没有把kube-state-metrics纳入到metric-server范畴中,是因为他们的关注点本质上是不一样的。
- node_exporter:收集集群中各节点的数据。
- prometheus:整个监控告警平台的核心,即server端。
- alertmanager:实现监控报警,支持钉钉、邮件等。
- grafana:实现数据可视化。
Kubernetes监控告警主要流程,如下所示:
- 首先,Prometheus通过exporter监控端采集K8s节点、Pod的资源使用情况以及Pod的状态信息数据后,Server端使用pull模式主动拉取exporter端的数据,按照“metrics-name <label_name=value,……>”的格式存储时序数据;在 Kubernetes 下,Promethues 通过与 Kubernetes API 集成,可以实现自动发现,目前支持5中服务发现模式,分别是:Node、Service、Pod、Endpoints、Ingress;
- 其次,客户端这边通过PromQL语句从server端查询相关监控指标数据,另外还可以集成使用alertmanager服务发送告警信息;
- 最后,将prometheus作为grafana的数据源,由Grafana做前端界面展示,也可使用PromQL语句查询相关数据。
说明:Kubernetes和Prometheus监控告警组件部署网上有许多资料,这里过程略。
二.监控告警实现
1.资源类监控
监控内容: 针对Pod集合单位时间内的CPU、内存、网络流量等资源使用量监控告警。
- 说明:为什么不建议基于资源使用率告警,原因是当Pod未使用Limit声明限制资源时,会无限制的使用主机资源,在这种情况下使用使用率是不靠谱的也是没有意义的。
监控告警项目: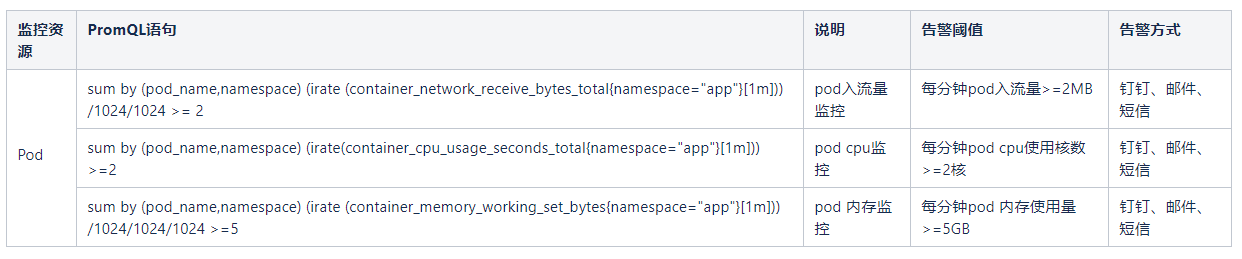
PromQL监控查询样图,如下所示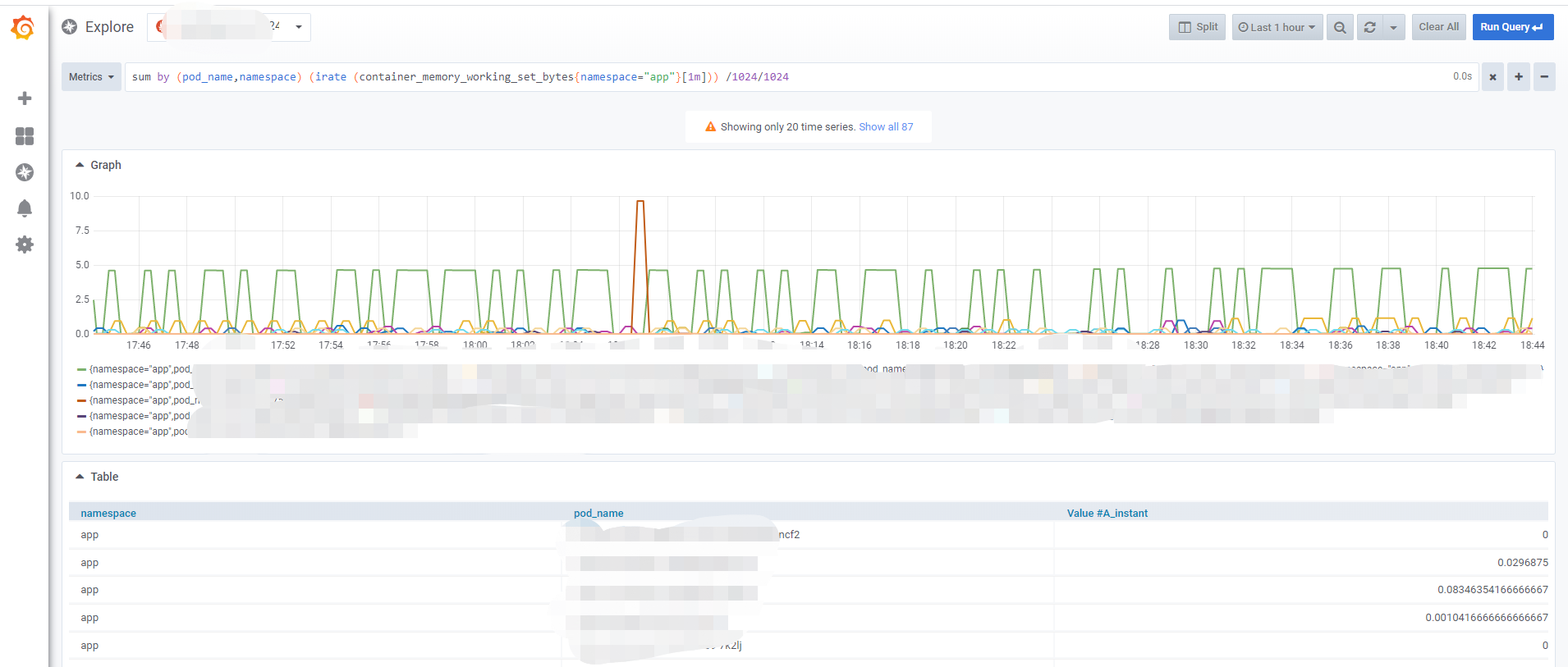
2.状态类监控
监控内容:针对Pod处于CrashLoopBackOff、Failed、Unknown等状态时告警,以及发生重启时则告警。
监控告警项目:
有了监控只是实现了第一步,还得需要告警来落地,更高端的用法是故障自愈。下一篇:Kubernetes Pod告警实现(二)