Spark介绍
Apache Spark 是用Scala语言开发的专为大数据处理而设计的计算引擎,类似于Hadoop MapReduce框架,Spark拥有Hadoop MapReduce所具有的优点,即Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark组件介绍,下图蓝色部分。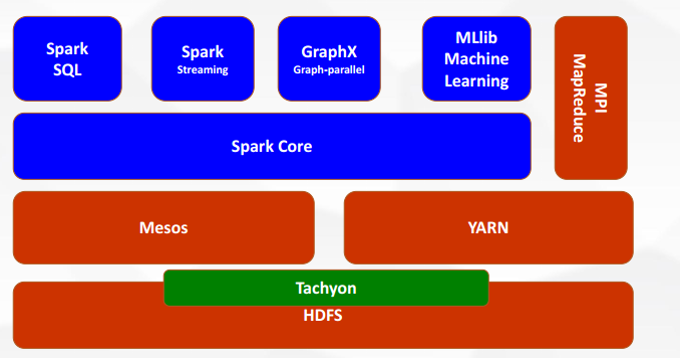
Spark有很多组件来解决使用Hadoop MapReduce时出现的问题。Spark有以下组件:
- Spark Core
- Spark Streaming
- Spark SQL
- GraphX
- MLlib (Machine Learning)
Spark Core
Spark Core是大规模并行和分布式数据处理的基础引擎。 核心是分布式执行引擎,Java,Scala和Python API为分布式ETL应用程序开发提供了一个平台。 此外,在核心上构建的其他库允许用于流式传输,SQL和机器学习的各种工作负载。 它负责:
- 内存管理和故障恢复
- 在群集上调度,分发和监视作业
- 与存储系统交互
Spark Streaming
Spark Streaming是Spark的组件,用于处理实时流数据。支持实时数据流的高吞吐量和容错流处理。 基本流单元是DStream,它基本上是一系列用于处理实时数据的RDD(弹性分布式数据集)。
Spark SQL
Spark SQL是Spark中的一个新模块,它使用Spark编程API实现集成关系处理。 它支持通过SQL或Hive查询查询数据。 对于那些熟悉RDBMS的人来说,Spark SQL将很容易从之前的工具过渡到可以扩展传统关系数据处理的边界。
Spark SQL通过函数编程API集成关系处理。 此外,它为各种数据源提供支持,并且使用代码转换编织SQL查询,从而产生一个非常强大的工具。以下是Spark SQL的四个库。
- Data Source API
- DataFrame API
- Interpreter & Optimizer
- SQL Service
GraphX
GraphX是用于图形和图形并行计算的Spark API。 因此,它使用弹性分布式属性图扩展了Spark RDD。
MlLib (Machine Learning)
MLlib代表机器学习库。 Spark MLlib用于在Apache Spark中执行机器学习。
Spark架构分布
下面来看看spark各个节点的分布图,如下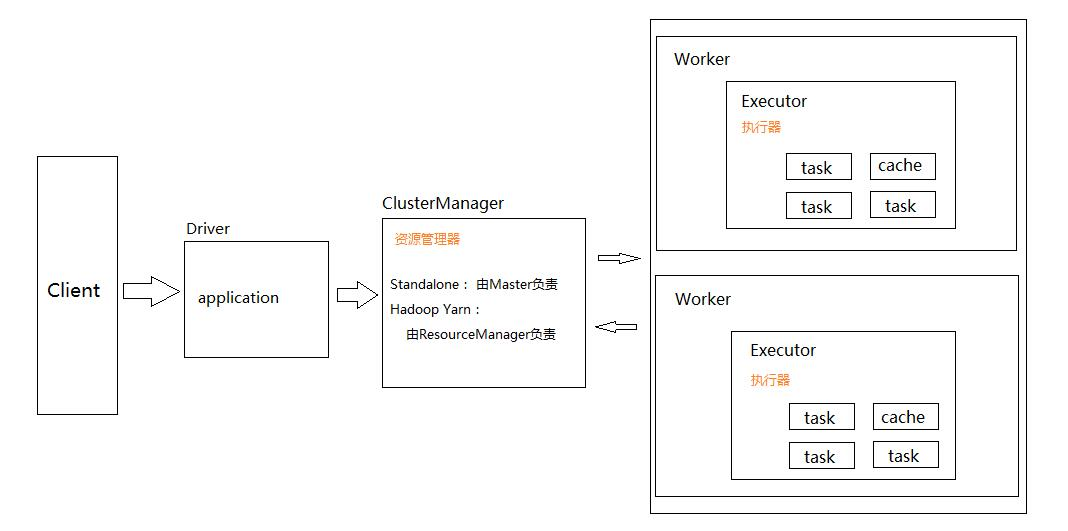
Spark采用的是Master-Slave模型,从上面可以看出分为四个部分,Client、Driver、ClusterManager、Worker。
- client:客户端进程,负责提交job到master
- Driver:运行Application,主要是做一些job的初始化工作,包括job的解析,DAG的构建和划分并提交和监控task
- Cluster Manager:在standalone模式中即为Master主节点,控制整个集群,监控worker,在YARN模式中为资源管理器ResourceManager
- Worker:负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,启动Driver。Executor,即真正执行作业的地方,一个Executor可以执行一到多个Task
使用基于Hadoop的Spark
Spark与Hadoop兼容性的。 因此,这是一种非常强大的技术组合。Hadoop组件可以通过以下方式与Spark一起使用:
- HDFS:Spark可以在HDFS之上运行,以利用分布式存储。
- MapReduce:Spark可以与MapReduce一起用于同一个Hadoop集群,也可以单独作为处理框架使用。
- YARN:可以使Spark应用程序在YARN上运行。
- 批处理和实时处理:MapReduce和Spark一起使用,其中MapReduce用于批处理,Spark用于实时处理。
Spark各组件应用场景
Spark的生态系统主要包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX 等组件。Spark生态系统组件的应用场景: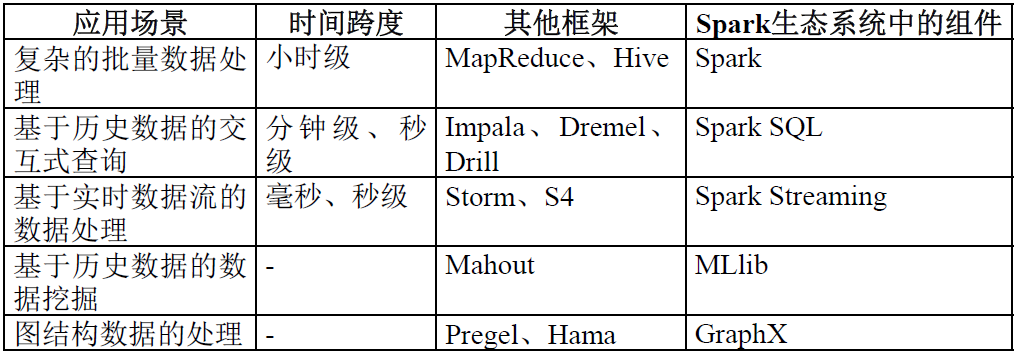
有了Hadoop,为什么使用spark
1、Spark Streaming是基于Spark实现的高吞吐与低延迟的分布式流处理系统。与Hadoop Storm相比,两者在功能上是一致的,都实现了数据流的实时处理;但Storm的延迟在豪秒级别,而Spark Streaming是在秒级别,所以在一些实时响应要求高的应用场景中,需要使用Storm。
2、由于Hadoop生态系统中的一些组件所实现的功能,目前是无法由Spark取代的,比如Storm、HDFS。现有的Hadoop组件开发的应用,完全转移到Spark上需要一定的成本,不同的计算框架统一运行在YARN中,可以带来如下好处:
- 计算资源按需伸缩
- 不用负载应用混搭,集群利用率高
- 共享底层存储,避免数据跨集群迁移
3、实际上,Spark可以看作是Hadoop MapReduce的一个替代品而不是Hadoop的替代品。
Hadoop和Spark优缺点
- 使用Hadoop进行迭代计算非常耗资源。MapReduce是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。
- Spark将中间结果保存在内存中,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据。
- Hadoop Storm在实时延迟度上比Spark Streaming好很多,前者是纯实时(纯实时的流式处理框架,即来一条数据就处理一条数据),后者是准实时(对一个时间段内的数据收集起来再做处理)。而且,Storm的事务机制、健壮性 / 容错性等特性,都要比Spark Streaming更加优秀。
spark三种部署模式区别和介绍
Spark支持的主要三种分布式部署方式分别是standalone、spark on mesos和 spark on YARN。
- standalone模式,即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。它是Spark实现的资源调度框架,其主要的节点有Client节点、Master节点和Worker节点。
- spark on yarn模式,yarn是统一的资源管理机制,在上面可以运行多套计算框架,如map reduce、storm等根据driver在集群中的位置不同,分为yarn client和yarn cluster。生产环境上一般使用yarn cluster模式。
- spark on mesos模式,mesos是一个更强大的分布式资源管理框架,它允许多种不同的框架部署在其上,包括yarn。
一般,Spark使用CDH安装部署,具体步骤,请参考:Centos7安装大数据平台CDH 6.2